
You can learn a lot by building a command-line AI agent (Part 1: The Router)
Building "Shade": Lessons from creating a custom AI tool that uses local LLMs

A few weeks ago, I built my own command line coding agent. There are a few reasons I started this project, sorted here in an honest order.
More tokens: I tend to use up the daily tokens allotted by my commercial coding agents (Claude, Q, Kiro). When I hit those limits, I want my own agentic coder to keep up the momentum.
Nostalgia: I’m a relic of the MS-DOS era and I like the dopamine hit I get when I drop into a command line. The recent wave of command-line agents use nostalgic ASCII interfaces, and I wanted to create a useful tool myself using that 80’s style.
Learning something new: I like taking things apart to see how they work, even if they don't always work when I put them back together. To be a great engineer or great product manager, you need to understand the entire product experience, and I want to understand how coding agents actually work and how to make them even better.
I want to know just how powerful a system of local models can be: I’ve been experimenting with local models running on my own machine lately. Here in mid-2025 they're good enough to accomplish a variety of analyses and coding tasks, and I want to see just how good they can be when used correctly. I believe the future for LLMs is “local first”. We’re in the dial-up modem phase right now, but we’re quickly headed towards a future where highly-performant LLMs will run efficiently on resource-constrained devices.
Over the next few posts, I’ll describe how I built “Shade”, and what I learned during the process. I’m not expecting Shade to be a replacement for professional command line agents, but I am finding it to be a capable coding partner on my projects when I need it to be. Here’s a quick preview of Shade in action:
A simple agent
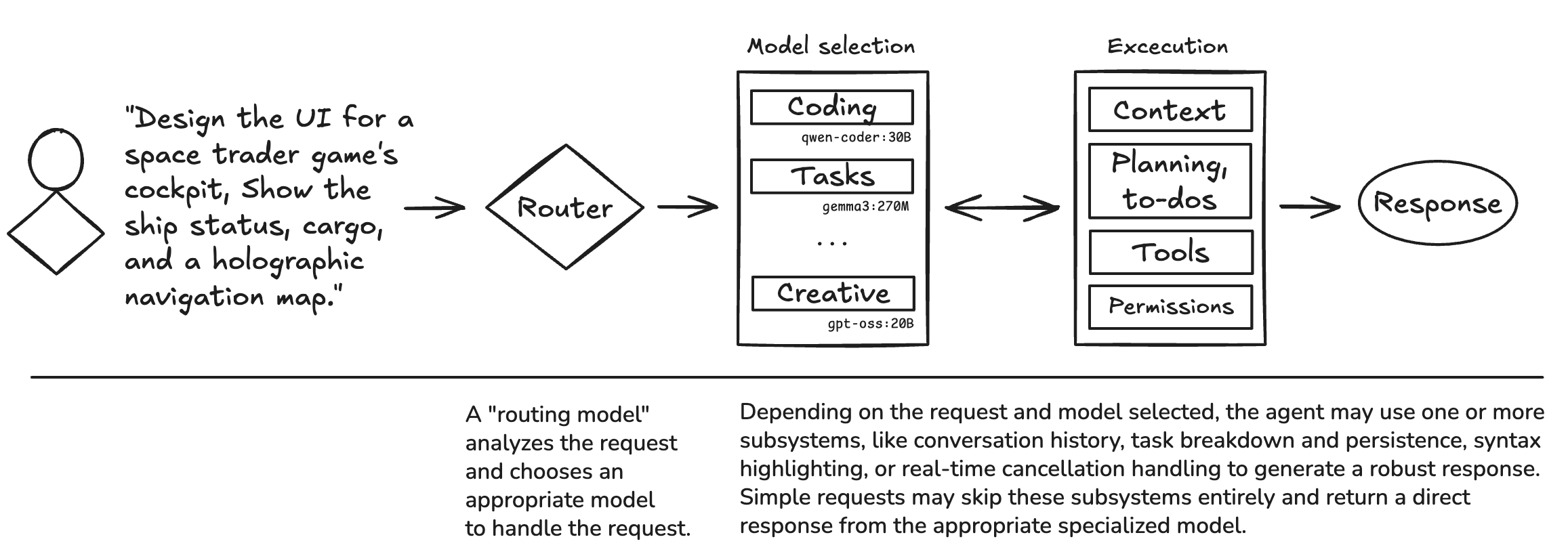
The most simple agent is one that just takes a request, sends it to a model, and returns a response. There is no context beyond maybe the current conversation, no tools involved, no memory of previous sessions, no ability to break down a request into complex tasks.

This is adequate for one-off requests or basic conversations, but to build something that can actually help you accomplish real work, you need much more than this.
A robust agent
A robust agent needs to handle context, decide if it needs to access the filesystem, make system calls, make network calls, ask for clarification, break down complex tasks, manage conversation history across sessions, route requests to specialized models, handle request cancellation, persist task state, provide real-time feedback during long operations, and much more. And even though I’m building Shade to be a helpful coding assistant, it should also be able to handle non-coding requests.
A note about my setup
I use Ollama and the Ollama APIs to interact with local models I’ve downloaded to my machine.
I run this on a 2023 MacBook Pro (Apple M3 Max) and 36GB of RAM. I haven’t tested it on anything less than 36GB but I suspect you can get away with this using 24GB of RAM, too.
Inside the router
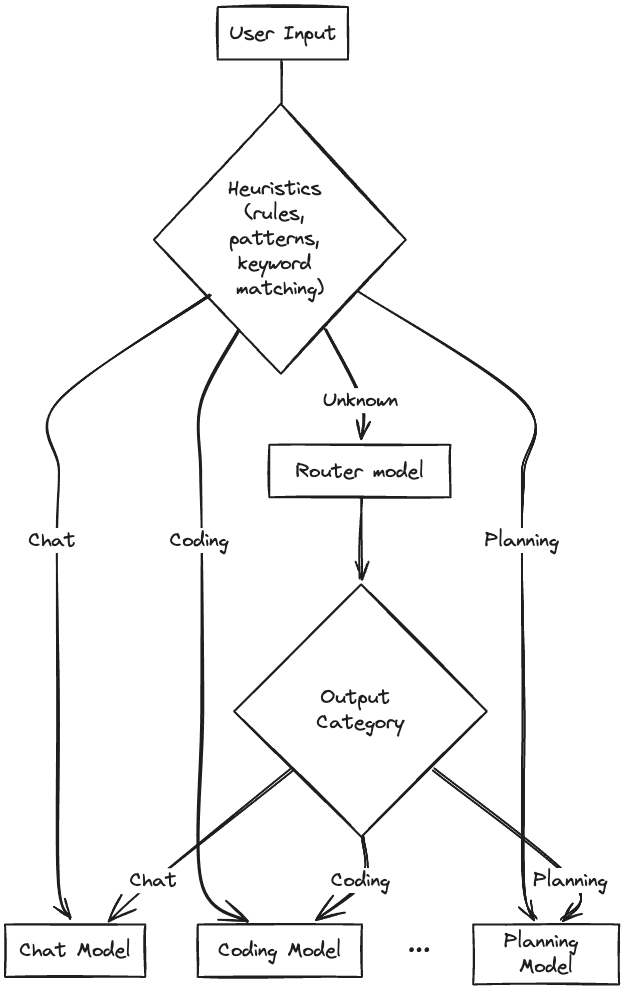
The "front door" to the agent is the router. The purpose of the router is to take an incoming request and determine which local model is best suited to handle the request. The router uses a hybrid approach: fast heuristic rules handle obvious cases in under 100ms, while ambiguous requests fall back to a “router model”. Right now the router model classifies incoming requests into 1 of 3 categories:
Chat
General conversation, explanations, Q&A, summaries.
Default “catch-all” if no other category fits.
Coding
One-shot code questions (“write me a function,” “fix this error”).
Optimized for simple coding requests
Planning
Anything that requires stepwise action or a structured plan, even if it’s coding.
Example: “Add a new field to my schema, write migrations, test, and deploy.”
Output: JSON task list, subtasks, execution order.
Instead of using one large model for everything, I can use different smaller models optimized for the right type of work. I built a “/model” command into Shade that allows me to configure the model/category mapping to be whatever I want, making it easy to experiment to pick the best model for the job.
When I first started working on the router, I assumed I might have to fine-tune a model to get good results. But I actually got really good results just with prompting. Here's an example of the prompt I use to classify a request:
You are a routing classifier. Your job is to analyze user input and determine which type of AI model would be best suited to handle their request.
Here's the user's input: [ user input... ]
You MUST respond with exactly one of these categories:
**Chat** – For general conversation, explanations, Q&A, or summaries. This is the default catch-all if no other category fits.
Examples: "Tell me a story", "How are you?", "Explain how GPT tokenization works", "Compare React vs Vue", "Who is the CEO of Nvidia?"
**Coding** – For one-shot coding requests that require direct code output, simple bug fixes, or implementation details.
Examples: "Write a hello world in Assembly", "Create a function in Rust", "Fix this bug", "Generate a SQL query for this table"
**Planning** – For requests that require stepwise action or a structured plan, even if they involve coding. The goal is to break the work into subtasks with execution order.
Examples: "Add a new last_updated field to my schema, write migrations, test, and deploy", "Break down this project into tasks", "What steps to launch a website?", "Plan my vacation to Japan", "Create a checklist for preparing for a job interview"
Analyze the user input and respond with ONLY the category name that best fits their request.You could also build your own model for this using "traditional" (non-transformer-based) machine learning, since this is essentially a decades-old classification problem. Ten years ago when I was at Alexa, we spent a considerable amount of time thinking about and experimenting with intent classifiers. It turns out a few rules and some good regular expressions will help you correctly route the myriad of different ways someone might ask to set a timer or turn off lights or play music; and if you can't confidently make a match, you fall back to a small classifier.
For this project, I do something similar. I take a hybrid approach that combines hard-coded heuristics with model routing. If the heuristics fail to make a confident match, I fall back to a model to do inference on the input. This approach gives me the best of both worlds: sub-100ms routing for obvious cases, while still handling nuanced queries that require semantic understanding.
Regardless of the model selected, I want the "time to first token" (TTFT) to be as low as possible, but not trade off too much accuracy. I experimented with 6 different models, using datasets of 100 short (5-10 word) phrases (e.g., "Write retry code for this API that uses exponential backoff") and 100 long (2-4 paragraph) instructions.
Here were the results of hammering each LLM with these requests:
The gemma3:4b model performed best, classifying requests in less than a quarter of a second with >90% accuracy. Surprisingly, it even beats OpenAI’s gpt-oss:20b model in accuracy, despite being 5 times smaller.
What’s next for the router
There are a few areas for experimentation and improvement for the router. Here are a couple I’ll be working on as I continue to improve Shade:
More robust heuristics. There are improvements that could be made to the heuristics to make it cover more edge cases and skip the penalty for invoking the router model. If I’m optimizing Shade to be a coding agent, this might mean weighting “guesses” by the router to automatically select the Coding model.
Different router models for different requests. Reading an incident report from Anthropic on a recent outage gave me the idea that there could be different router models depending on the length of the incoming request. Does using a small model for the router for small requests, and a large model for the router for larger requests increase accuracy, especially for the larger requests?
What I learned
Simple wins
I reconfirmed my belief that simple solutions can often get the job done. There have been too many times over my career I’ve seen someone (or even an entire team) try to solve something with a complex solution, when a simple solution can work as well or better. There’s a saying in baseball about Caribbean players trying to make it to the major leagues: “you don’t walk off the island.” A walk is the high-percentage, steady (boring) play that keeps innings alive and can help your team more often. A 450-foot homer is low-probability but spectacular, and spectacular gets you noticed. It might even get you off the island. So players swing for the fences, even though the safer play can win more games.
Classifying a user’s intent with regex and/or a prompt isn’t as flashy as creating a new algorithm or even fine-tuning a custom model (which I’ll still experiment with), but it does the job fast and it does the job well.
The little things matter
The router was the first part of the system I built, which meant I spent quite a bit of time getting the UI and UX right before writing any code for the router logic. One of the challenging things about supporting models from multiple providers is supporting the different ways they output content. I spent time making sure the output looked uniform no matter where it came from. I spent even more time fixing UI issues like broken borders or artificial line breaks that occur when you resize a window in the terminal while Shade is running.
I borrowed lots of great ideas from Claude Code and Q Developer, but took some of the things that bothered me from both and fixed them in Shade. For example, letting a user quit by typing “/quit”, “/q”, “stop”, “exit”, Ctrl+C, Ctrl+D, or even misspelling “quit” (e.g., “/qiut”)
What’s next
Out of all the components in this stack, the router was probably the easiest to build, given its straightforward duties. In the next post, I'll dive into one of the most complex pieces: managing a single context across multiple models that have various context window sizes.