
Input > Output

In 2023, Andrej Karpathy tweeted that "The hottest new programming language is English", referring to how we’re able to prompt AI to generate code instead of writing it out line-by-line. But the irony is most of us are using this “new programming language" the same way we used the old ones, pecking away at keyboards to translate our thoughts into text. Lately, I’ve tried talking instead.
For the past 4 weeks, I’ve been experimenting with Wispr Flow, a dictation tool which makes the promise of using its real-time transcription app to be “up to 4x faster than typing.” Over that period I used Wispr to interact with various coding agents1, dictating over 27K words with an average dictation speed of 135 words-per-minute.
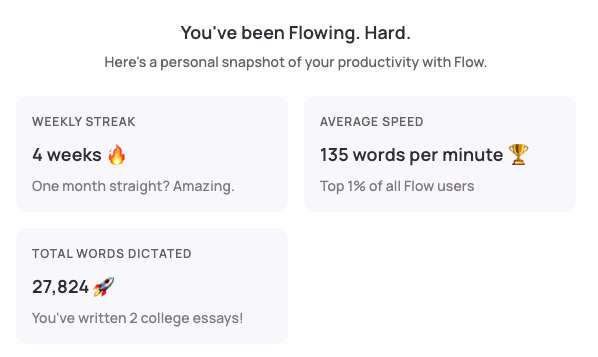
To see how much of an improvement I was getting over typing, I did a quick experiment of three different typing tests at 30-seconds each. My average speed was 87 WPM with 97% accuracy. So when I am able to “talk” to a large language model to generate code, it’s roughly 1.5x faster than typing to it. I’m not seeing the 4x improvement, but my average typing WPM is a bit faster than the median2.
Last week I watched an interview between the co-founder of Cursor, Michael Truell and Open AI president Greg Brockman, discussing the launch of GPT-5. In it, Truell talked about how GPT-5 was really good about detecting “thorny bugs” when you “give it a lot of detail up front.” If you’ve used LLMs long enough you’ll have had a similar experience. The more details you can give about a task, the better results you’ll get on the first try. But when we're typing those details at 40-90 words per minute we we hit a “thought-to-task” bandwidth bottleneck.
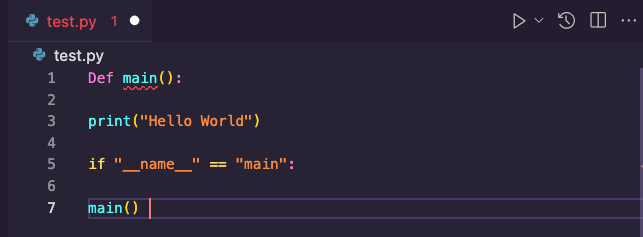
Doctors and lawyers and writers have been transcribing this way for years. But now that it’s possible to build software by prompting an LLM, developers can join that list. It’s a lot easier to speak “write a simple Hello World program in Python” than to speak Python to write code — “def main parenthesis new line print hello world newline if underscore underscore name equals main newline main” turns into;
But what's really convinced me to use voice more in my coding is that dictation tools have matured significantly over the past 18 months. I’d been trying this for a while with Apple’s built-in dictation, but it was subpar, and you had to speak out the punctuation. Wispr handles punctuation effortlessly, and impressively figures out what I'm actually trying to say even when I backtrack or change direction mid-sentence. To give you an example of this, I talked to Wispr while simultaneously recording a session using Voice Notes. Here was the transcript from Voice Notes:
Let's, um let's create a new utility app for the Mac, and it should live in the menu bar at the top. And all I want you to do is when I click the button, I want you to be able to or when I click the icon, I want you to be able to clean up my desktop. That is, move anything that's not in a folder into a folder. But what I want you to do is make sure that the folders are organized. So if there are pictures in the desktop, for example, they should go into a pictures folder. Or if there are documents, they should go in their own documents folder, but keep those doc folders separate. So if they're a PDFs, there should be a PDF folder. If there are word docs, make a word doc folder, et cetera.
Here’s the output from Wispr:
Let's create a new utility app for the Mac, and it should live in the menu bar at the top. All I want you to do is when I click the icon, I want you to be able to clean up my desktop. That is, move anything that's not in a folder into a folder. But what I want you to do is make sure that the folders are organized. So if there are pictures on the desktop, for example, they should go into a pictures folder. Or if there are documents, they should go in their own documents folder. But keep those document folders separate. So if there are PDFs, there should be a PDF folder. If there are Word docs, make a Word doc folder, et cetera.
There’s only a 16-word difference between the two, but Wispr understood that I’d changed my mind about “clicking the button” when I realized “clicking the icon” would be a better instruction. I’m able to think out loud and have those thoughts turn into a coherent idea. I could get there typing, but I can get there 1.5x faster by using my voice.
Marginal gains
I’ll take the 1.5x improvement. This doesn’t mean I’m ditching the keyboard. I use the keyboard much more often than I use dictation, and probably always will. But voice is a shortcut I’m starting to lean on much like I use keyboard shortcuts when I’m coding. I’m finding voice especially useful at the beginning of projects, or when I’m going back and forth with the model on a feature I want it to build or update.
What I’m optimizing for is my thought-to-task bandwidth, not my typing speed. The real win is capturing an idea before it evaporates while I’m translating the idea into precise text.
There are a lot of GPUs being burned right now to help us optimize for output. But being able to 1.5x, 2x, or 4x your input goes a long way too.
Native microphone input isn’t built in to coding agents yet, but it’s easy enough to use Wispr’s shortcuts (the Fn key on the Mac keyboard) to transcribe directly into any text box in Kiro, Cursor, Claude Code, etc. in real time.