
You can learn a lot by building a command-line AI agent (Part 2: Context Management)
Building Shade's dynamic context manager which can adapt to any model

In Part 1, I described Shade’s router and how it plays an important role in a local-first, multi-model agent. In Part 2, I show the context management system, arguably the most important component of the system.
Context and multi-modal systems
A mutli-model system presents challenges when it comes to context. When the user chats with the agent, the router selects a model to handle the current request. But since models load with an empty context window1, that model has no idea about the previous conversation history. Just as you might find at a dinner party, we can't start talking to someone new and expect them to know what we've been talking about with other people. And just as some people may have different capacities for holding and understanding information, these models have varying context window sizes we need to understand.
The context engine in Shade solves the challenge of providing context by using a centralized context store, and adapting the context that is passed to a model so that it fits within that model's context window.
But how much context should we try to fit in that window? Studies show that even with very large context windows, an LLM's performance degrades when you reach a certain point. A group of researchers from The University of Hong Kong, ByteDance, and UI Urbana-Champaign showed that as of 2025, the optimal context length of an LLM is roughly half its context window size. Once you reach that threshold, the model’s output quality and speed of response start to degrade.
Experiments
Most of the research papers on context I came across rely on high-end GPUs like the NVIDIA H200. Since I'm building Shade to run locally, I wanted to see how models performed on the less-capable Apple M3 Max chip as you filled their context windows. I want two things out of the model: quality responses and a short time-to-first-token (TTFT). Quantifying output quality as the context grows is a topic for another post, but TTFT is relatively easy to measure.
I used six different open-source models, and tested how fast each model produced the first token with the context window filled at increments of 10% (from 10% up to 100%). To ensure fair comparisons, I used identical pre-generated standardized technical text at varied token lengths for all models; repetitive but grammatically correct content to eliminate content complexity as a variable.
I tried to control the hardware state as much as possible to give the fairest results. My test script waited for the CPU to have < 10% utilization before each test, and I unloaded models (resetting the content window) between tests for consistent cold starts.
While I anticipated performance degradation as context windows filled up, the differences between model sizes and the steepness of some curves surprised me. This chart plots TTFT against context window usage (%) for six models:
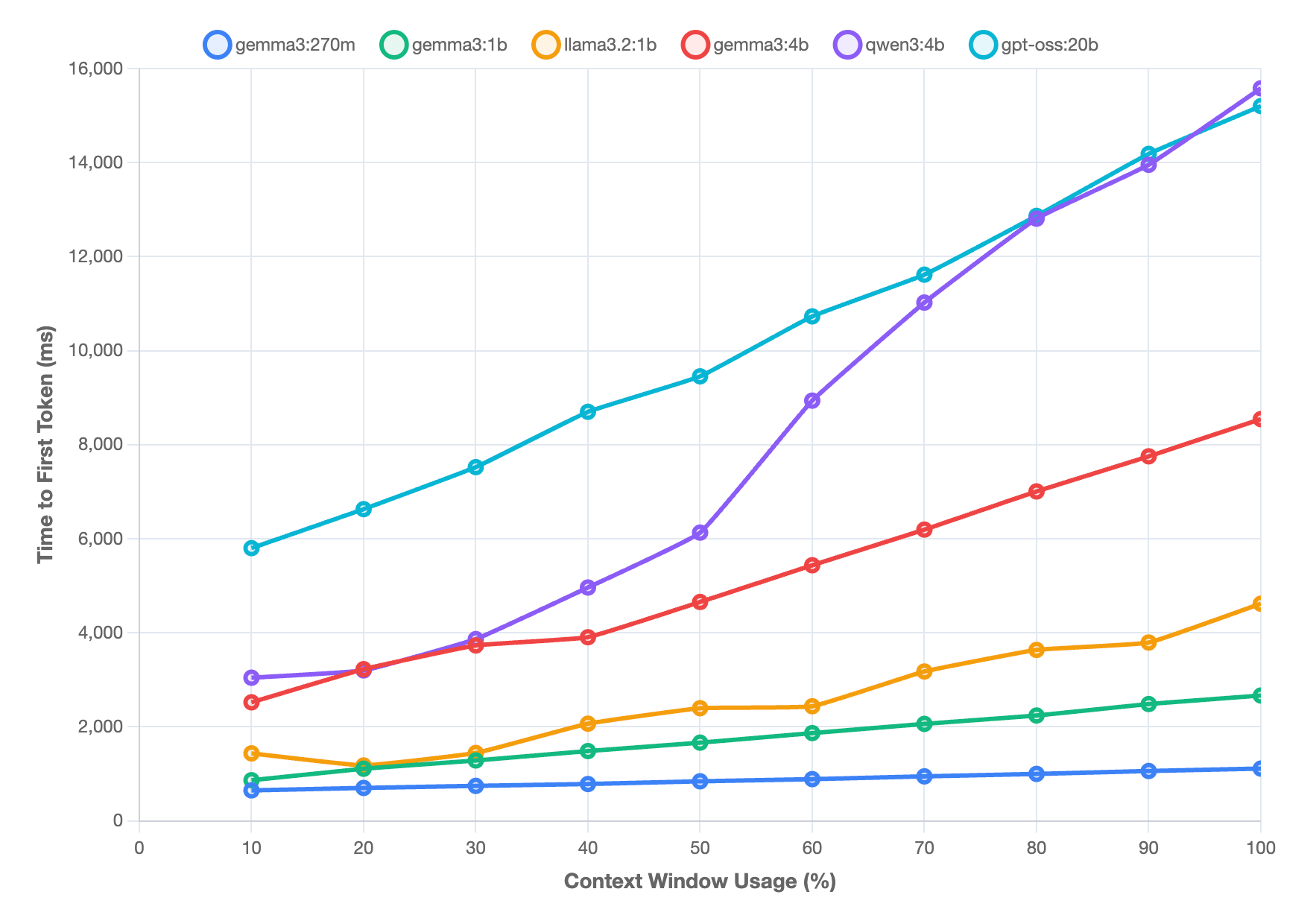
The smaller models — gemma3:270m and gemma3:1b — show very modest growth, staying well under 3 seconds for TTFT, even at full context. Meta’s llama3.2:1b comes in third, but still tops out at around 4.5 seconds. The larger models however (gemma3:4b, qwen3:4b, and gpt-oss:20b) climb much more steeply. Most scale in a roughly linear fashion, but qwen3:4b shows the sharpest acceleration: it stays relatively stable until about 30–40% usage, then latency spikes, pushing it past 10 seconds by 70% and ending near 16 seconds. OpenAI’s gpt-oss:20b, with its 20B parameters, is consistently slow across all context sizes, tracking just under qwen3:4b at the high end. Google’s gemma3:4b lands somewhere in the middle, scaling more steadily up to about 8.5 seconds. What I learned is that overall, smaller models scale gently with context size, while larger ones face significant latency penalties, with qwen3:4b emerging as the most susceptible and worst performer at high context loads. Importantly for Shade, it looks like the sweet spot for these models (especially larger models) is to keep context between 40-50% of the context window.
Context engine internals
Coding agents like Q and Claude Code and Gemini all offer a compaction feature that allows a user to compress the conversation. This compaction can happen via a variety of methods, like using lightweight encoders to summarize all the previous input. But I've used these agents long enough to know that showing the ever-decreasing amount of space left in the context window hangs over me like a dread, and I feel the need to run “/compact” even though I know when I do the quality in the rest of my conversation usually degrades. I find myself trying to tailor my inputs to squeeze the most out of the precious space I have remaining, because I know once I compact the flow I was in is now gone. This is likely because even after compaction, the content in the window often still exceeds that magical 40-50% threshold.
I wanted to take a different approach with Shade. I don't want to use compaction, and I don't want the user to have to worry about context windows. I chose not to show how much context they’ve used, or how much they have left. I believe these systems should abstract away as much cognitive overhead as possible, and for me that means not worrying about the length of my conversation. Of course if you're wanting to load a large codebase into Shade, it probably won't handle that well, but that's not a use case I'm optimizing for.
To manage context, I use a simple SQLite database. The complete chat history for a session is stored in a simple “conversations” table:
CREATE TABLE conversations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp INTEGER NOT NULL,
role TEXT NOT NULL CHECK(role IN ('user', 'assistant')),
content TEXT NOT NULL,
tokens INTEGER,
model_used TEXT
);I keep a count of the tokens with gpt-tokenizer, so that I know how much of the conversation I can pass along to models. I also run a background process that summarizes2 the entire conversation, and store it in a table as well:
CREATE TABLE summary (
id INTEGER PRIMARY KEY,
content TEXT NOT NULL,
tokens INTEGER NOT NULL,
covers_up_to_id INTEGER NOT NULL,
created_at INTEGER NOT NULL
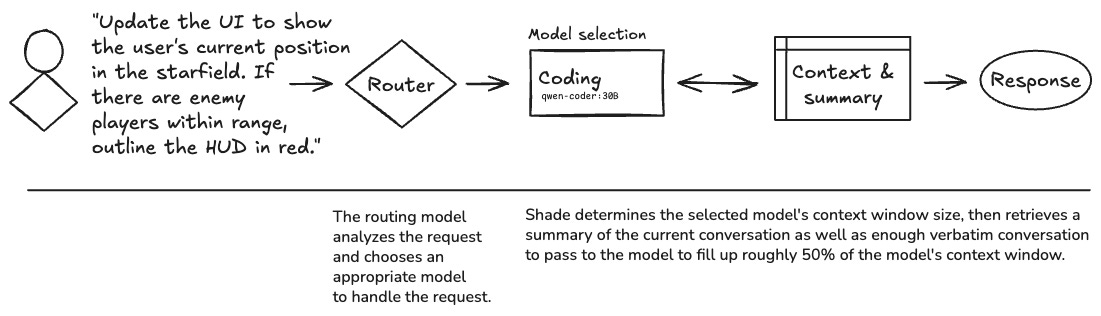
);When the router sends the conversation to a new model, it passes three pieces of content to the model:
The most recent request
The summary of the conversation (from the `summary` table)
Enough verbatim content from `conversations` to fill up to 45% of the context window size (which is the content window size - the number of tokens in the recent request + the number of tokens in the summary).
What I learned
The most important thing I learned while building the context engine for Shade is that no one has solved context yet. I don't get excited when I see a new model boast about a 1M+ token context limit. What it really means is I might rely on good performance up to 400-500K tokens, and even then I’d be skeptical of performance.
From the papers I read while working on the Shade context engine, researchers are grappling with what I discovered through my experiences and experiments: performance degrades with longer input contexts, and models lose accuracy as context length approaches the window size. They lose focus on key information, making it harder to find needles in the haystack.
The best thing about no one having solved the problem yet means there's not a "right way" to do this yet. I’m sure the way I’m handling context in Shade can be done better, but until the problem is solved I’m finding that my way gets the job done.
Most models load with a “system prompt”, which takes up a relatively small portion of the context window. I’m ignoring system prompts in my experiments.
The summarization is accomplished with a background process that uses a prompt with gpt-oss:20b. If the total length of the conversation exceeds gpt-oss:20b’s context window limit of 128K tokens, then I split the conversation into chunks, summarize each, and make one more call to the model to create a "summary of summaries.".